Introduction
applicable provides the following methods to analyze the applicability domain of your model:
- Principal component analysis
- Hat values statistics
Example
We will use the Ames IA housing data for our example.
There are 2,930 properties in the data.
The Sale Price was recorded along with 74 predictors, including:
- Location (e.g. neighborhood) and lot information.
- House components (garage, fireplace, pool, porch, etc.).
- General assessments such as overall quality and condition.
- Number of bedrooms, baths, and so on.
More details can be found in De Cock (2011, Journal of Statistics Education).
The raw data are at http://jse.amstat.org/v19n3/decock/AmesHousing.txt but we will use a processed version found in the AmesHousing package. applicable also contains an update for these data for three new properties (although fewer fields were collected on these).
To pre-process the training set, we will use the recipes package. We first tell the recipes that there is an additional value for the neighborhood in these data, then direct it to create dummy variables for all categorical predictors. In cases where there are no levels observed for a factor, we eliminate predictors with a single unique value, then estimate a transformation that will make the predictor distributions more symmetric. After these, the data are centered and scaled. These same transformations will be applied to the new data points using the statistics estimated from the training set.
library(recipes)
library(dplyr)
# Load custom houses from applicable.
data(ames_new, package = "applicable")
ames_cols <- c('MS_SubClass', 'Lot_Frontage', 'Lot_Area', 'Lot_Shape',
'Neighborhood', 'Bldg_Type', 'Year_Built', 'Central_Air',
'Gr_Liv_Area', 'Full_Bath', 'Half_Bath', 'Longitude', 'Latitude')
training_data <-
ames |>
# For consistency, only analyze the data on new properties
dplyr::select(any_of(ames_cols)) |>
mutate(
# There is a new neighborhood in ames_new
Neighborhood = as.character(Neighborhood),
Neighborhood = factor(Neighborhood, levels = levels(ames_new$Neighborhood))
)
training_recipe <-
recipe( ~ ., data = training_data) |>
step_dummy(all_nominal()) |>
# Remove variables that have the same value for every data point.
step_zv(all_predictors()) |>
# Transform variables to be distributed as Gaussian-like as possible.
step_YeoJohnson(all_numeric()) |>
# Normalize numeric data to have a mean of zero and
# standard deviation of one.
step_normalize(all_numeric())Principal Component Analysis
The following functions in applicable are used for principal component analysis:
-
apd_pca: computes the principal components that account for up to either 95% or the providedthresholdof variability. It also computes the percentiles of the principal components and the mean of each principal component. -
autoplot: plots the distribution function for pcas. You can also provide an optional set ofdplyrselectors, such asdplyr::matches()ordplyr::starts_with(), for selecting which variables should be shown in the plot. -
score: calculates the principal components of the new data and their percentiles as compared to the training data. The number of principal components computed depends on thethresholdgiven at fit time. It also computes the multivariate distance between each principal component and its mean.
Let us apply apd_pca modeling function to our data:
ames_pca <- apd_pca(training_recipe, training_data)
ames_pca
#> # Predictors:
#> 13
#> # Principal Components:
#> 44 components were needed
#> to capture at least 95% of the
#> total variation in the predictors.Since no threshold was provided, the function computed the number of principal components that accounted for at most 95% of the total variance.
For illustration, setting threshold = 0.25 or 25%, we now need only 10 principal components:
ames_pca <- apd_pca(training_recipe, training_data, threshold = 0.25)
ames_pca
#> # Predictors:
#> 13
#> # Principal Components:
#> 6 components were needed
#> to capture at least 25% of the
#> total variation in the predictors.Plotting the distribution function for the PCA scores is also helpful:
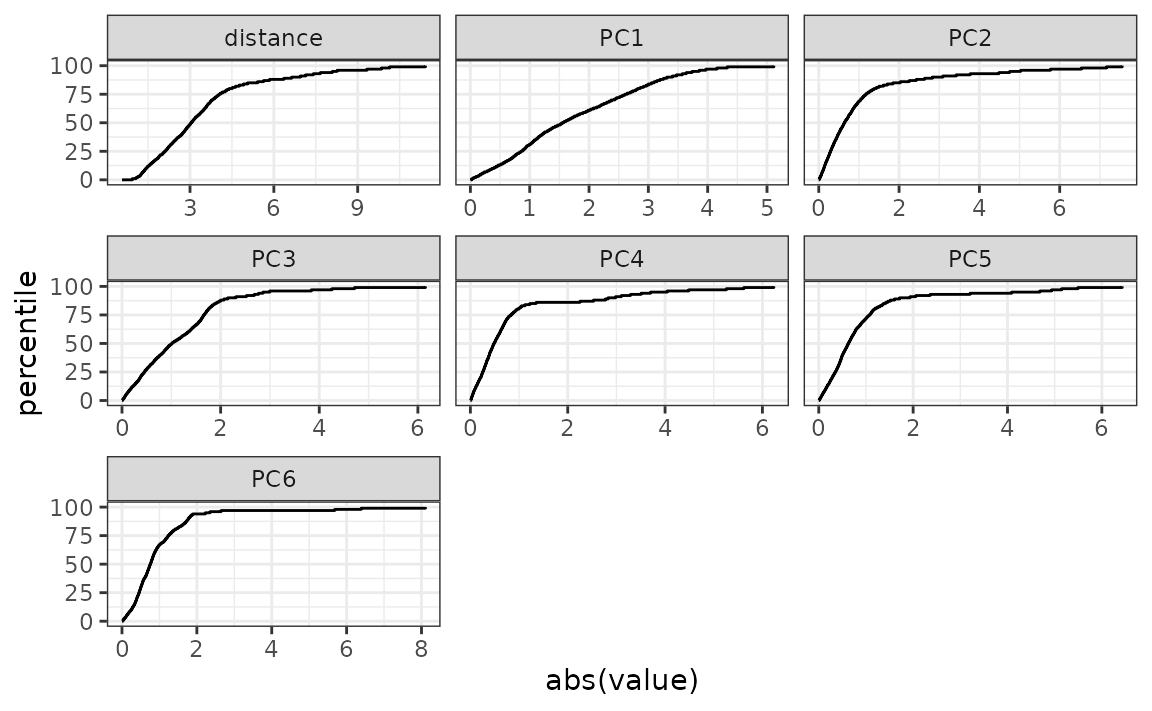
You can use regular expressions to plot a smaller subset of the pca statistics:
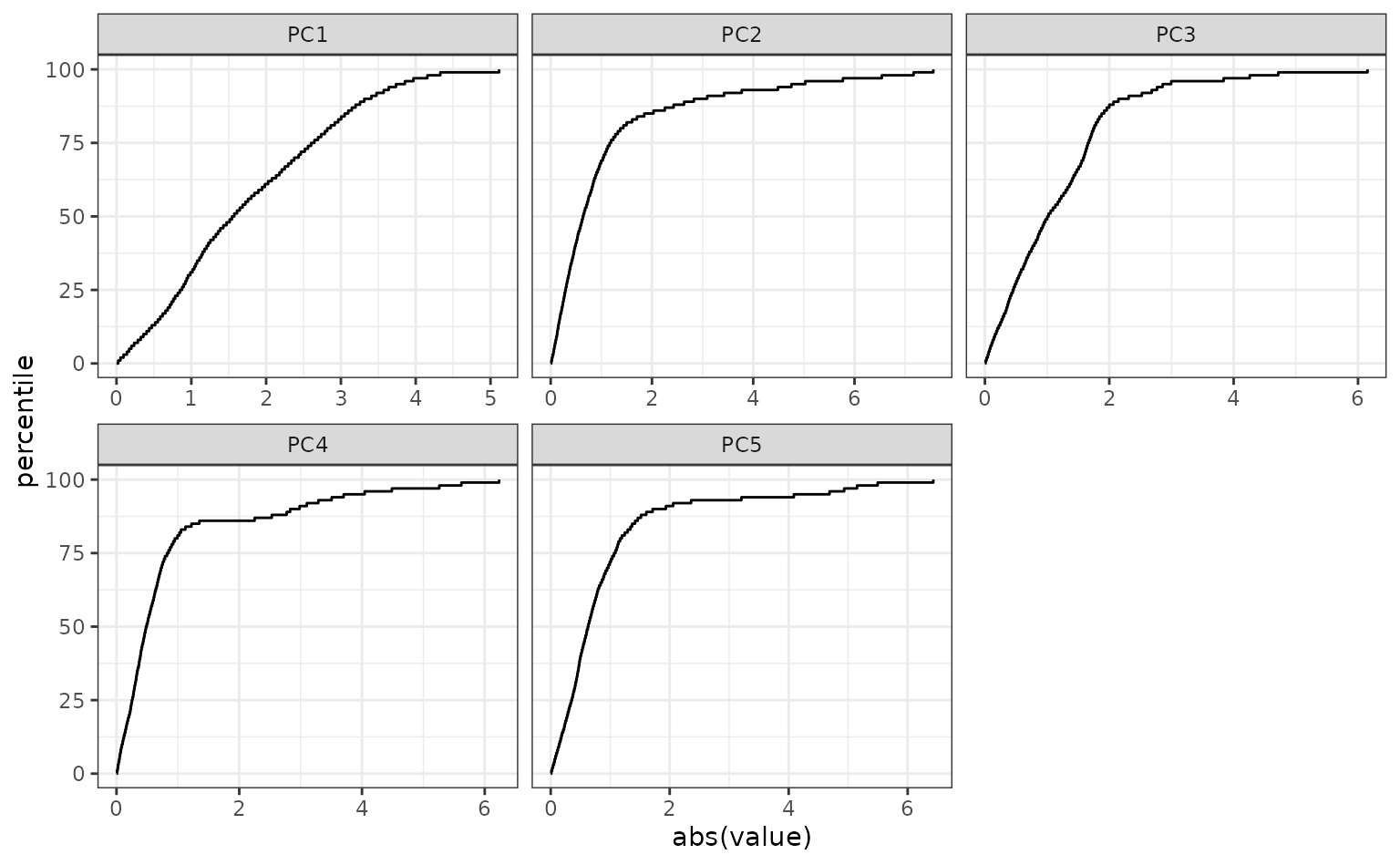
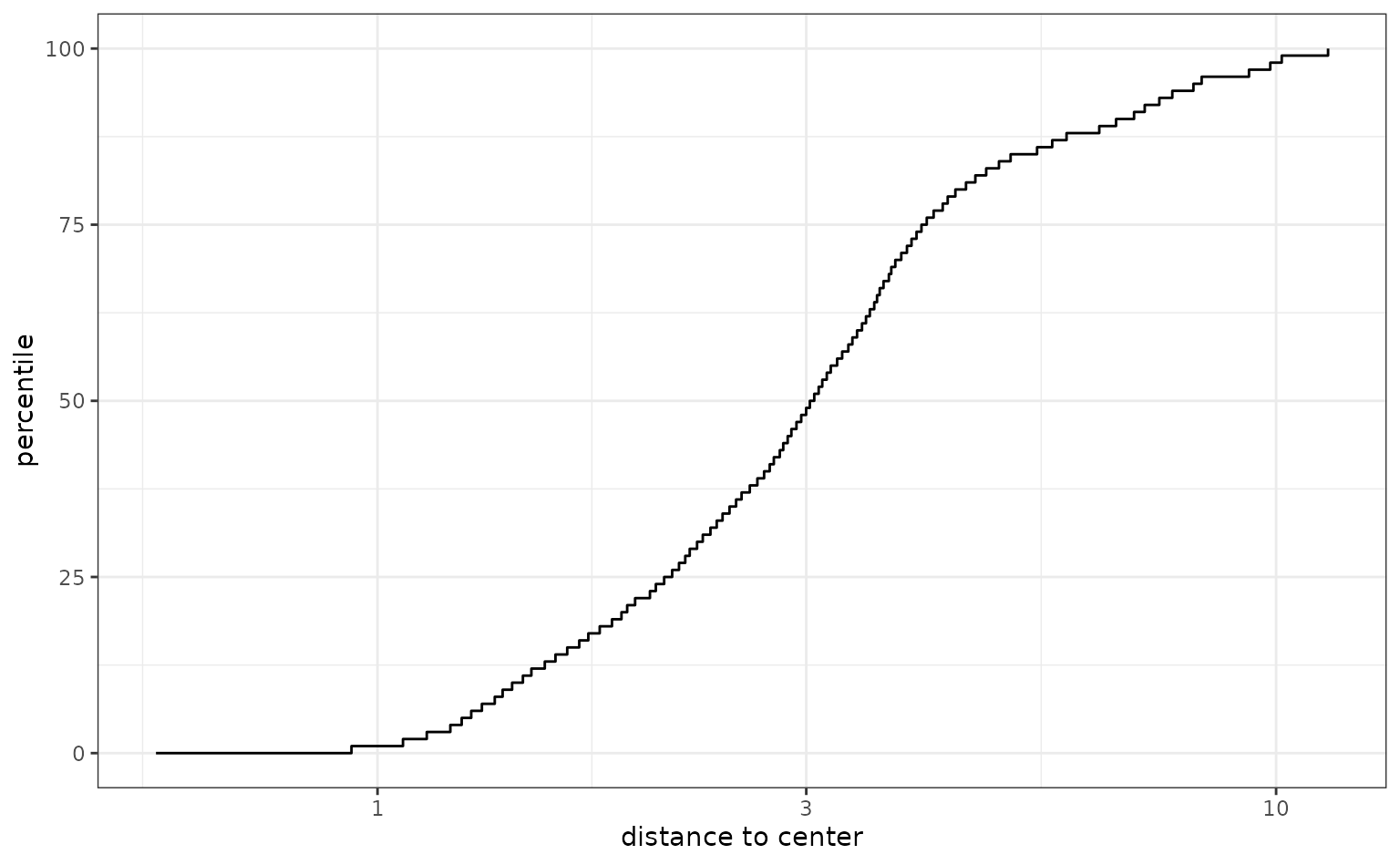
The score function compares the training data to new samples. Let’s go back to the case where we capture 95% of the variation in the predictors and score the new samples. Since we used the recipe interface, we can give the score function the original data:
Notice how the samples, displayed in red, are fairly dissimilar to the training set in the first component:
What is driving the first component? We can look at which predictors have the largest values in the rotation matrix (i.e. the values that define the linear combinations in the PC scores). The top five are:
These three houses are extreme in the most influential variable (year built) since they were new homes. The also tend to have fairly large gross living areas:
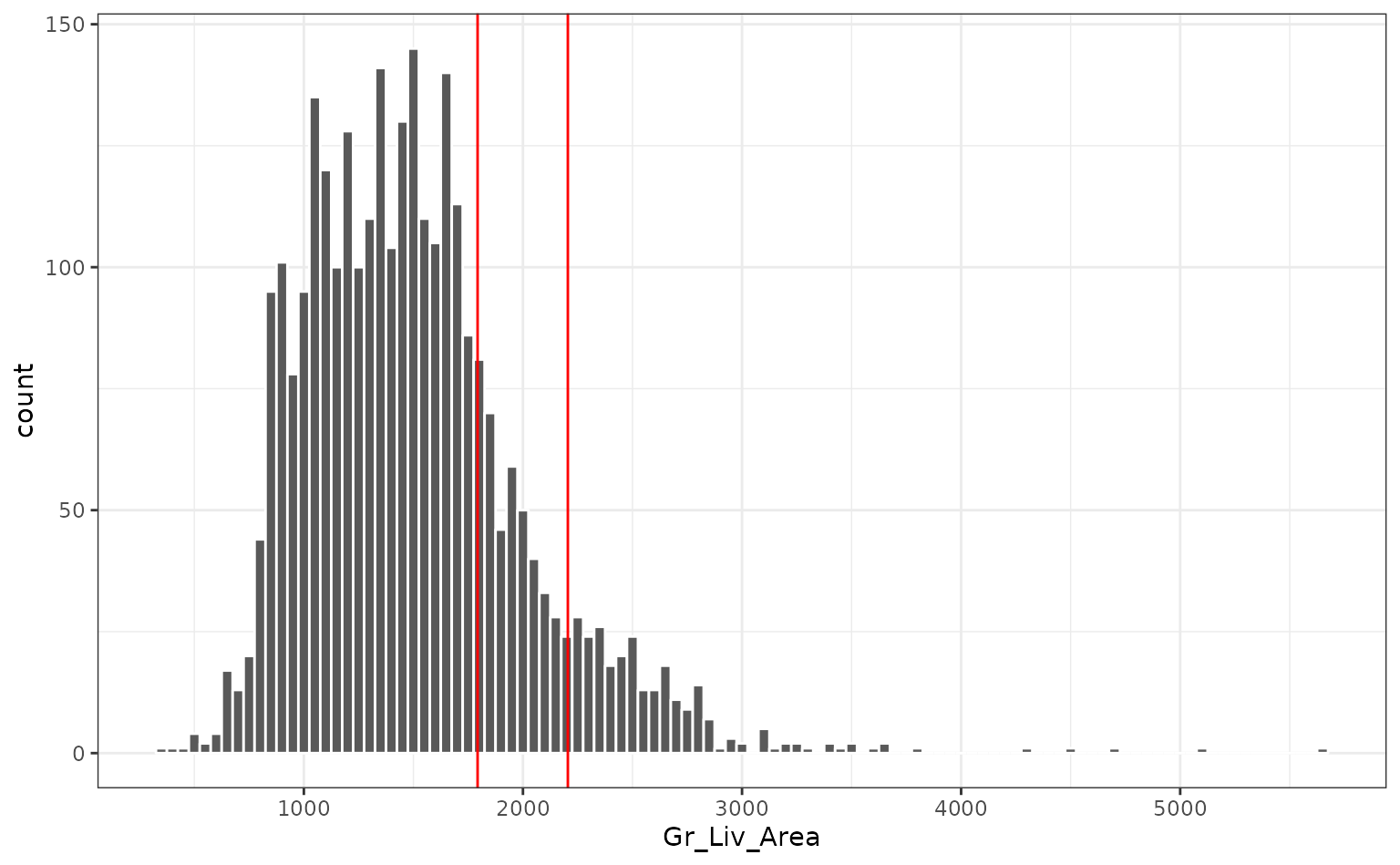
This may be what is driving the first component.
However, the overall distance values are relatively small, which indicates that, overall, these new houses are not outside the mainstream of the data.
Hat Values
The Hat or leverage values are based on the numerics of linear regression. The measure the distance of a data point to the center of the training set distribution. For example, if the numeric training set matrix was , the hat matrix for the training set would be computed using
The corresponding hat values for the training would be the diagonals of . These values can be computed using stats::hatvalues(lm_model) but only for an lm model object. Also, it cannot compute the values for new samples.
Suppose that we had a new, unknown sample (as a data vector ). The hat value for this sample would be
.
The following functions in applicable are used to compute the hat values of your model:
-
apd_hat_values: computes the matrix . -
score: calculates the hat values of new samples and their percentiles.
Two caveats for using the hat values:
The numerical methods are less tolerant than PCA. For example, extremely correlated predictors will degrade the ability of the hat values to be effectively used. Also, since an inverse is used, there cannot be an linear dependencies within . To resolve this the former example, the recipe step
recipes::step_corr()can be used to reduce correlation. For the latter issue,recipes::step_lincomp()will identify and remove linear dependencies in the data (as shown below).When using a linear or logistic model, the model adds an intercept columns of ones to . For equivalent computations, you should add a vector or ones to the data or use
recipes::step_intercept().
Let us apply apd_hat_values modeling function to our data (while ensuring that there are no linear dependencies):
non_singular_recipe <-
training_recipe |>
step_lincomb(all_predictors())
# Recipe interface
ames_hat <- apd_hat_values(non_singular_recipe, training_data)
options(prev_options)